
1 life 2 live
[통계 공부] 메타코드M - 데이터 분석 (통계 기초의 모든것) 5장-2 본문
5. 연속확률분포: 정규분포의 특징

표본분포(sampling distribution)
: 모집단에서 일정한 크기로 뽑을 수 있는 표본을 모두 뽑았을 때, 그 모든 표본의 통계량의 확률분포
→ 통계량(평균, 표준편차, 분산, 중위값 등)
표본평균의 평균과 표준편차
: X1, … , Xn이 모평균 μ, 모표준편차 σ인 모집단으로부터의 확률표본(i.i.d)일 때,
→ X1, … , Xn이 서로 독립이며 같은 분포에서 나왔기 때문에 모평균 μ를 따른다.(E(X1)=μ, … , E(Xn)=μ)
→ 분산의 경우 원 데이터보다 밀집되어있는 경향이 있음.(중심값을 나타내기 때문)
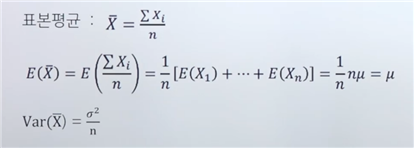
5. 연속확률분포: 중심극한정리

중심극한정리(central limit theorem, CLT)
: 평균이 μ, 표준편차가 σ인 임의의 모집단으로부터 크기 n인 표본에서의 표본평균은 n이 크면 근사적으로 평균이 μ이고 분산이 σ²/n인 정규분포를 따름
: 모집단이 정규분포라면 표본평균은 표본 개수와 상관없이 항상 정규분포를 따른다.
→ ex) 키의 평균이 정규분포를 따른다.
→ n이 30보다 크거나 같을 경우 또는 모집단이 정규분포를 따른다면 표본평균 X는 정규분포를 따른다.
5. 연속확률분포: 카이제곱 분포
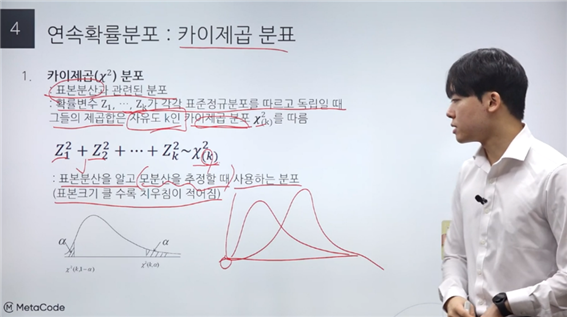
카이제곱(χ²) 분포
: 표본분산과 관련된 분포
: 확률변수 Z1, … , Zk가 각각 표준정규분포를 따르고 독립일 때 그들의 제곱합은 자유도 k인 카이제곱 분포 χ²(k)를 따름

: 표본분산을 앍고 모분산을 추정할 때 사용하는 분포
(표본크기 클 수록 치우침이 적어짐)

→ 표본분산= 통계량, 확률변수 Z1= 정규분포를 따르는 확률변수를 표준화 한 값, 자유도 k: 모수 ← 모양 결정, 확률변수 Z를 각각 제곱해서 더할 때 그 갯수를 의미.
→ 표본 분산은 S의 제곱이므로 확률변수의 값이 반드시 양의 값을 가진다.
→ Positive Skewness, 표본 크기가 크면 정규분포에 근사
'빅데이터' 카테고리의 다른 글
| [통계 공부] 메타코드M - 데이터 분석 (통계 기초의 모든것) 6장-1 (2) | 2024.02.09 |
|---|---|
| [통계 공부] 메타코드M - 데이터 분석 (통계 기초의 모든것) 5장-3 (1) | 2024.02.06 |
| [통계 공부] 메타코드M - 데이터 분석 (통계 기초의 모든것) 5장-1 (2) | 2024.02.01 |
| [통계 공부] 메타코드M - 데이터 분석 (통계 기초의 모든것) 4장 (0) | 2024.01.31 |
| [통계 공부] 메타코드M - 데이터 분석 (통계 기초의 모든것) 3장-2 (2) | 2024.01.25 |



