
1 life 2 live
[통계 공부] 메타코드M - 데이터 분석 (통계 기초의 모든것) 2장 본문
개인적으로 공부한 내용을 정리하려고 한다.
아래 사이트에서 동영상을 보고 공부 중이다.
상당히 효과적인 것 같다.
메타코드M
빅데이터 , AI 강의 플랫폼 & IT 현직자 모임 플랫폼ㅣ메타코드 커뮤니티 일원이 되시기 바랍니다.
mcode.co.kr

3. 통계량 - 산포
1. 분산(Variance)
- 편차 제곱의 합을 자료의 수로 나눈 값

2. 표준편차(Standard Deviation)
- 분산을 제곱근한 값

→ 원 데이터의 스케일을 맞추기 위해 표준편차를 많이 사용
cf) n-1을 해주는 이유?
모집단의 모수 추정을 위해 통계량을 구하는데, 불편추정량(편향이 없다 = 모수와 추정량의 기댓값이 같다)을 만족하기 위해 n-1로 나눈다.
3. 통계량 – 산포: 예제

3. 통계량 - 형태
1. 왜도(Skewness)
- 분포의 비대칭도

→ if skew > 0, mode < median < mean(극단값에 영향 많이 받음)
1. 첨도(Kurtosis)
뾰족한 정도
- 표준정규분포의 첨도는 3이 된다.
3. 통계량 - 상관
- 상관(Correlation)
- 확률변수 X, Y의 변화가 서로 있을 때 상관관계가 있다고 함
- 선형적 관련성을 파악함
2. 공분산(Covariance)
두 데이터(확률변수)의 선형적 연관성(x, y) 확인(스케일 없음 → 데이터 단위에 따라 값이 달라짐)
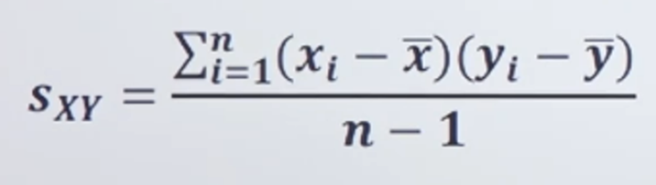
3. 상관계수(Correlation Coefficient)(피어슨 상관계수↓)
공분산을 두 변수의 표준편차 곱으로 나눈 값(r = Sxy / Sx*Sy)
-1 < r < 1
두 양적 변수 간의 선형적 연관성의 강도 측정(비선형적인상관계수도 존재하지만 다루지 않음)
단위가 없음
절댓값이 1에 가까울 수록 연관성의 강도가 높다

4. 확률과 확률변수: 확률 정의
Randomness(무작위성) *
사건(event)(=사상)
- 표본공간(S): 랜덤한 현상의 모든 가능한 결과의 집합
- 사건(event): 표본공간의 부분집합
합사상 A∪B
곱사상 A∩B
여사상
배반사상 A∩B = ∮
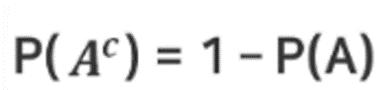
- Flipping Coin Twice
표본공간 S: {HH, HT, TH, TT}
사건 A: 동전을 두 번 던지는 시행에서 동전의 앞면이 1번만 A = {HT, TH}
4.확률의 고전적 정의
: 가능한 결과가 N가지이고, 각 결과가 나타날 가능성이 모두 같을 때, 사건 A에 속하는 결과가 m개라면 A의 확률
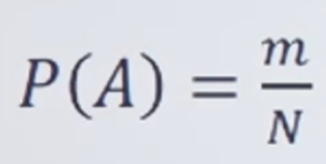
5. 경험적 정의(상대도수)
:무한대로 경험하는 것(MC Simulation과 연관)
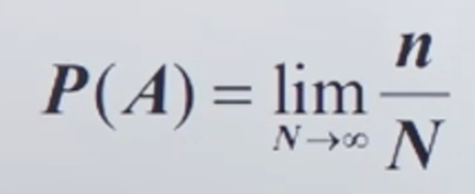
- 확률의 공리적 정의
: 표본공간 S에서 임의의 사상 A에 대하여,
0 ≤ P(A) ≤1
P(S) = 1
서로 배반인 사상들에 대하여

이때, P(A)를 사상 A의 확률이라고 함
→ 표본공간 S는 전체집합(모든 경우)이므로 확률이 1이다.
- 확률의 성질

'빅데이터' 카테고리의 다른 글
| [통계 공부] 메타코드M - 데이터 분석 (통계 기초의 모든것) 3장-2 (2) | 2024.01.25 |
|---|---|
| [통계 공부] 메타코드M - 데이터 분석 (통계 기초의 모든것) 3장-1 (1) | 2024.01.24 |
| [통계 공부] 메타코드M - 데이터 분석 (통계 기초의 모든것) 1장 (0) | 2024.01.19 |
| Hilbert transform (1) | 2023.11.09 |
| Zero-shot Learning, Few-shot Learning의 차이 (1) | 2023.11.02 |


